Bloom Filters in C#: a visual introduction

A Bloom filter is a data structure used to test if an element is a member of a set or not. It was invented by Burton Howard Bloom in 1970. The Bloom filter uses multiple hash functions to map the input data to a bit array. Let’s see together how it works. We’ll start with a bit of theory that helps to understand how it works, and then we’ll look at a direct example in C#.
Bloom Filters: The Theory
A Bloom filter is based on the idea of hashing, which is a process of mapping data of arbitrary size to data of a fixed size. The Bloom filter uses multiple hash functions to map the input data to a bit array. The bit array is then used to represent the set. The Bloom filter is a space-efficient data structure because it does not store the actual elements of the set. Instead, it stores the hash values of the elements in the set. This makes it possible to represent very large sets with a small amount of memory.
One of the key advantages of Bloom filters is that they are very fast. Both the add and contains operations have a time complexity of O(1). However, there is a trade-off between speed and accuracy. Bloom filters have a non-zero probability of returning a false positive, which means that it may indicate that an element is in the set when it is not. The probability of a false positive can be controlled by adjusting the size of the bit array and the number of hash functions used. In many cases, however, we just need to quickly verify that an element is not in a set. This is where the Bloom filter can significantly improve the performance of our software. Check out this visual example of using a Bloom Filter to reduce disk accesses.
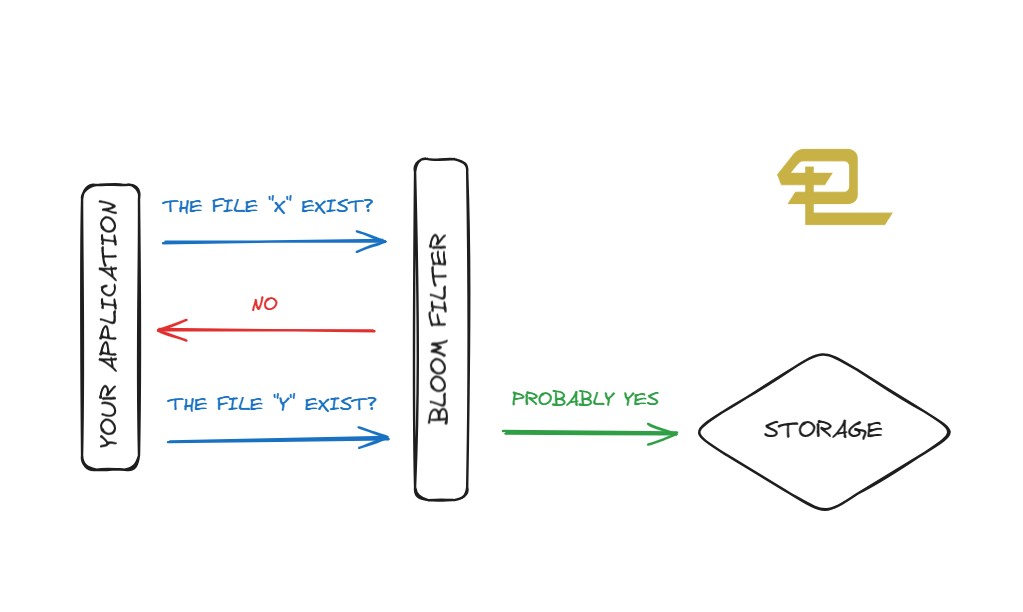
Bloom Filters: How it work
Bloom filter algorithms use a bit array and multiple hash functions. When an item is added to the bloom filter, it undergoes a series of hash operations, and the bits at the calculated positions are set to 1 (refer to the image below). To check if an item is present, the same hash calculations are performed, and if the bits at the calculated positions are all set to 1, the item is potentially present. However, if even one of those bits is 0, the item is definitely not present. Since false positives can occur, the algorithm is considered probabilistic, but it compensates by offering extremely high performance.
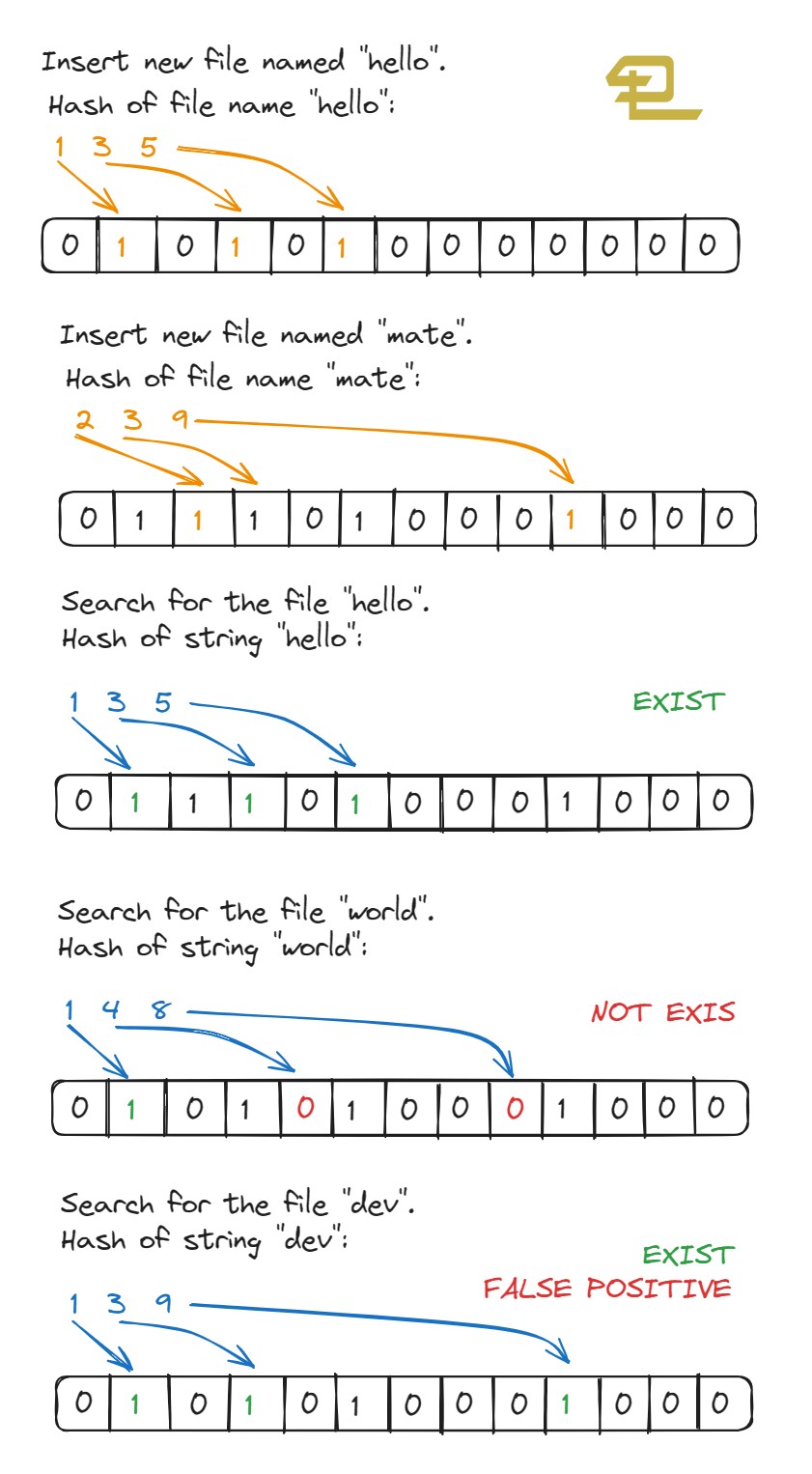
Bloom Filters: The C# Implementation
In C#, implementing a Bloom filter is relatively straightforward. The following code snippet demonstrates how to create a Bloom filter using the System.Collections.BitArray class:
public class BloomFilter {
private readonly BitArray _bits;
private readonly int _hashCount;
///
/// Initializes a new instance of the
/// The expected number of elements the filter
/// will hold.
/// The desired false positive probability rate,
/// must be between 0 and 1 (exclusive).
/// Thrown if the error
/// rate is not between 0 and 1 (exclusive).
public BloomFilter(int capacity, double errorRate) {
var bitArraySize = GetBitArraySize(capacity, errorRate);
_bits = new BitArray(bitArraySize);
_hashCount = GetHashCount(capacity, bitArraySize);
}
///
/// Adds a new string value to the Bloom filter.
///
/// The string value to add to the filter.
public void Add(string value) {
var hashValues = GetHashValues(value);
foreach (var hashValue in hashValues) {
_bits[hashValue] = true;
}
}
///
/// Checks if a string value is possibly in the Bloom filter.
///
/// The string value to check for presence
/// in the filter.
/// true if the value might be in the set; false if the
/// value is definitely not in the set.
public bool Contains(string value) {
var hashValues = GetHashValues(value);
foreach (var hashValue in hashValues) {
if (!_bits[hashValue]) {
return false;
}
}
return true;
}
///
/// Generates hash values for a given string.
///
/// The string to hash.
/// An array of integers representing hash values
/// for the input string.
private int[] GetHashValues(string value) {
var hashValues = new int[_hashCount];
using (MD5 md5Hash = MD5.Create()) {
var hashBytes = md5Hash.ComputeHash(Encoding.UTF8.GetBytes(value));
for (var i = 0; i < _hashCount; i++) {
int startIndex = (i * 4) % hashBytes.Length;
hashValues[i] = Math.Abs(BitConverter.ToInt32(hashBytes, startIndex)) % _bits.Length;
}
}
return hashValues;
}
///
/// Calculates the size of the bit array needed to achieve a
/// desired false positive rate for a given capacity.
///
/// The expected number of elements
/// in the Bloom filter.
/// The desired false positive rate.
/// The size of the bit array.
/// Thrown if the error
/// rate is not between 0 and 1 (exclusive).
private static int GetBitArraySize(int capacity, double errorRate) {
if (errorRate <= 0 || errorRate >= 1) {
throw new ArgumentOutOfRangeException(nameof(errorRate), "Error rate must be between 0 and 1 (exclusive).");
}
var size = -(capacity * Math.Log(errorRate)) / (Math.Log(2) * Math.Log(2));
return (int)Math.Ceiling(size);
}
///
/// Determines the optimal number of hash functions to use based
/// on the filter's capacity and bit array size.
///
/// The expected number of elements in the Bloom filter.
/// The size of the bit array.
/// The optimal number of hash functions to use.
private static int GetHashCount(int capacity, int bitArraySize) {
var count = (bitArraySize / capacity) * Math.Log(2);
return Math.Max(1, (int)Math.Round(count));
}
}
Let's test the filter
Here is the code to test our new Bloom Filter:
class TestClass {
static void Main(string[] args) {
Console.WriteLine("Start tests");
// Instance a new BloomFilter Object
BloomFilter bf = new BloomFilter(100, 0.1);
// Generate 100 random strings
const string chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
var random = new Random();
var stringList = new List();
for (int i = 0; i < 100; i++) {
var stringaCasuale = new StringBuilder(50);
for (int j = 0; j $lt; 50; j++) {
stringaCasuale.Append(chars[random.Next(chars.Length)]);
}
stringList.Add(stringaCasuale.ToString());
}
// Add generated random strings to the bloom filter
foreach (string str in stringList) {
bf.Add(str);
}
// Check if the bloom filter find all strings
foreach (string str in stringList) {
var resultExist = bf.Contains(str);
if(!resultExist) {
throw new Exception("Bloom filter not work: not find a string that exist!");
}
}
// Check for a string that not exist
var ressultNotExist = bf.Contains(chars);
if (ressultNotExist) {
throw new Exception("Bloom filter not work: false positive!");
}
Console.WriteLine("Tests ended!");
}
}
Bloom Filters in C#: Conclusion
In this article, we’ve explored the theory behind Bloom filters and how to implement them in C#. We’ve seen that Bloom filters are a space-efficient data structure that can be used to represent very large sets with a small amount of memory. They are also very fast, with both the add and contains operations having a time complexity of O(1).
However, there is a trade-off between speed and accuracy. Bloom filters have a non-zero probability of returning a false positive, which means that it may indicate that an element is in the set when it is not. The probability of a false positive can be controlled by adjusting the size of the bit array and the number of hash functions used.
Overall, Bloom filters are a useful tool for many applications, including spell checking, network routers, and database systems. They are also a great example of how probabilistic data structures can be used to solve complex problems.
Checkout BloomBloomFilter, a C# implementation available on NuGet.